大数据入门之Presto/Trino
Presto/Trino:是用来高速,实时,跨源的数据查询。
What is Presto ?

- Presto是由Facebook开发的分布式sql查询引擎,用来进行高速、实时的数据查询
- Presto的产生是为了解决Hive的MapReduce模型太慢且不能通过BI等工具展现HDFS的问题
- Presto是一个计算引擎,它不存储数据,通过丰富的connector获取第三方服务的数据,并支持扩展。可以通过连接Hive,来实现快速query hive table
- 可以跨数据源进行联合查询
查询例子:
1 | # 联合查询hive的表和mysql的表 |
Presto 数据模型:
- Catalog: 即数据源,Hive, Mysql都是数据源,Presto可以连接多个Hive,Mysql
- Schema: 类比于database,一个catalog下有多个schema
- table: 数据表,一个schema下有多个数据表
Presto 和Trino的关系
2020年12月PrestoSQL 更名为 Trino,所以Trino实际上是Prestode rebrand,至于为什么? 参考
说到底是Presto在Facebook的几个核心创始人员和公司闹掰了,然后出去后创立了新的公司为了Presto/Trino的发展。但是Facebook已经注册了Presto的商标权,所以不得已只能改名字了。
Presto架构
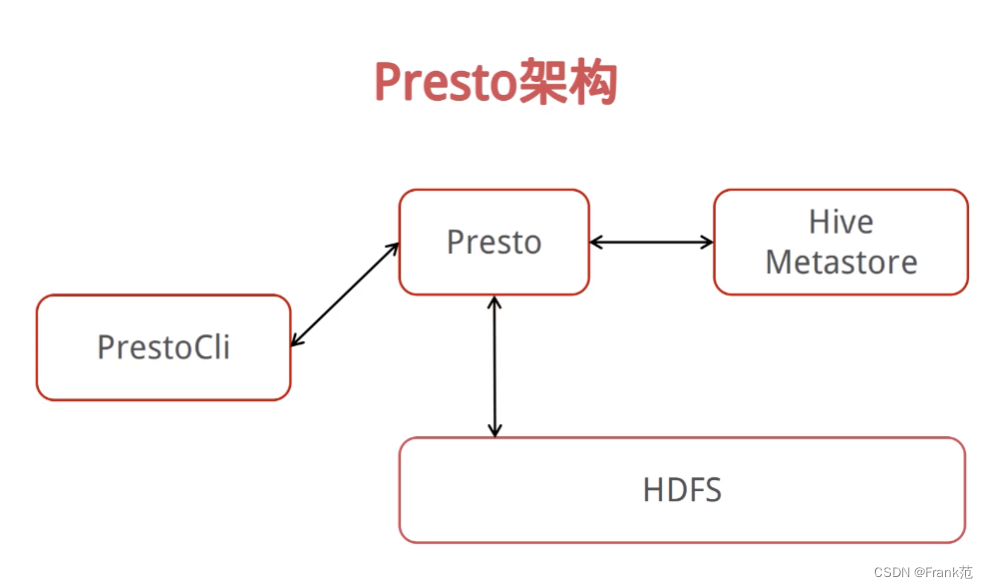
- Presto从Hive Metastore获取元数据信息;
- 获取元数据信息后,从HDFS访问数据;
- 最终讲结果返回给client。
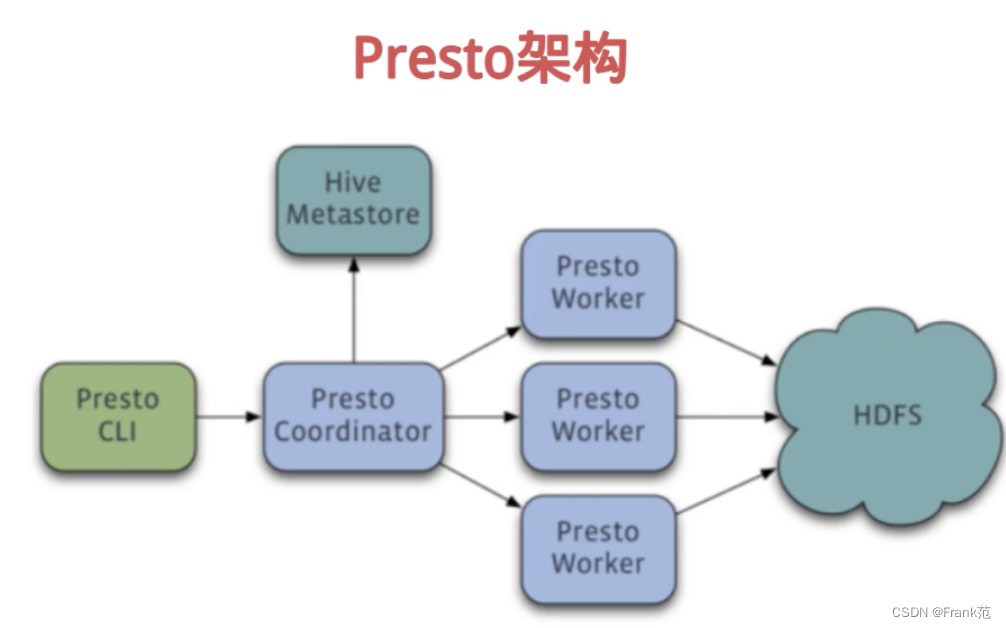
- Coordinator负责解析SQL语句,生成查询计划并访问Hive metastore,分发执行任务
- Discovery Server负责维护Coordinator和worker的关系,通常内嵌于Coordinator节点
- Worker负责执行查询任务以及于HDFS进行交互读取数据。
Presto VS Spark

pyhive访问presto
- pip package: presto
- 或者用sqlalchemy