大数据入门之Sqoop
Sqoop:解决的问题是提供了传统数据库和Hadoop之间转换的方案。
什么是Sqoop
- 用于在Hadoop和传统的数据库(Mysql, Postgresql)进行数据的传递。
- 可以通过Hadoop的MapReduce把数据从关系型数据库中导入到Hadoop集群。
- 传输大量结构化或半结构化数据的过程完全是自动化的。
- sqoop的导入进程是一个自动生成出来的java class,因此它的很多组件都可以自定义,比如导入的格式、文本的格式、到出的格式等等。
如下图所示: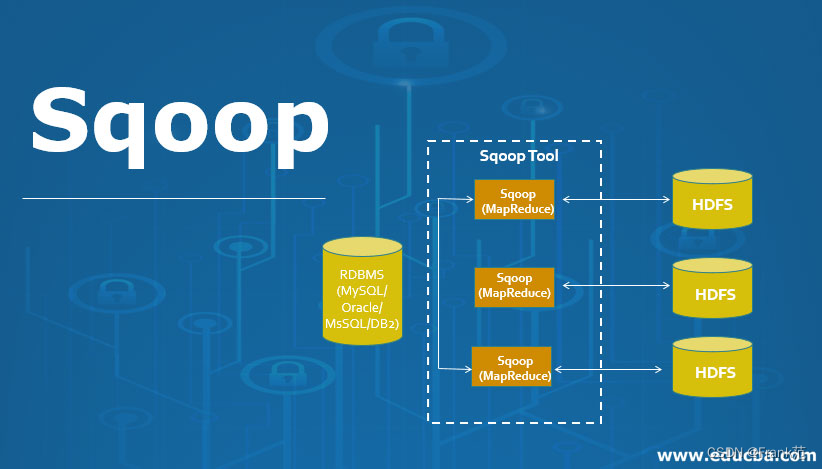
怎么用Sqoop
Sqoop 与 Mysql
- 连通测试
1 | sqoop list-databases \ |
- 查询指定数据库中所有数据表
1 | sqoop list-tables \ |
Sqoop与Hive
Mysql数据导入到Hive
Sqoop 导入数据到 Hive 是先将数据导入到 HDFS 上的临时目录,然后再将数据从 HDFS 上 Load 到 Hive 中,最后将临时目录删除。可以使用 target-dir 来指定临时目录。
1 | sqoop import \ |
导入到 Hive 中的 sqoop_test 数据库需要预先创建,不指定则默认使用 Hive 中的 default 库。
1 | # 查看 hive 中的所有数据库 |
验证:
1 | # 查看 sqoop_test 数据库的所有表 |
Hive 数据导到MySQL
由于 Hive 的数据是存储在 HDFS 上的,所以 Hive 导入数据到 MySQL,实际上就是 HDFS 导入数据到 MySQL。
查看Hive表在HDFS的存储位置
1
2
3
4# 进入对应的数据库
hive> use sqoop_test;
# 查看表信息
hive> desc formatted help_keyword; # Location: 可以知道对应的数据库存放在哪个位置导出命令
1
2
3
4
5
6
7
8sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hive \
--export-dir /user/hive/warehouse/sqoop_test.db/help_keyword \
-input-fields-terminated-by '\001' \ # 需要注意的是 hive 中默认的分隔符为 \001
--m 3